Database
- 데이터베이스는 체계화된 데이터의 모임이다.
- 여러 사람이 공유 및 관리하는 정보의 집합이다.
- 자료의 모음으로 검색과 갱신의 효휼화를 위해 고도로 구조화한 것이다.
- 자료 항목의 중복을 없애고 구조화하여 저장해놓은 자료의 집합체이다.
장점
- 중복 최소화
- 무결성 (정확한 정보를 보장)
- 일관성
- 독립성 (물리적/논리적)
- 표준화
- 보안유지
관계형 데이터베이스 RDB; Relation Database
- 서로 관련된 데이터를 저장하고 접근할 수 있는 데이터베이스 유형이다.
- 키와 값들의 간단한 관계를 표 형태로 정리한 데이터베이스이다.

스키마 Schema
데이터베이스에서 자료의 구조, 표현방법, 관계의 명세를 기술한 것이다.
아래의 이미지와 같이 id, name 등 해당 key의 이름과 데이터 타입을 정하여 명세표를 작성한다.
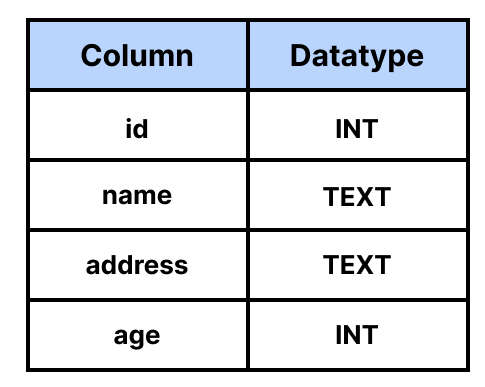
테이블
열(컬럼/필드), 행(레코드/값/row)의 모델을 사용해 조직된 데이터 요소들의 집합이다.
즉, 스키마의 명세를 바탕으로 테이블을 만들어 데이터를 알맞은 형식에 맞게 정렬한다.

열 column/filed
각 열에 고유한 데이터 형식을 지정한다.
name이란 열(column, filed)에 고객들의 이름 데이터가 저장된 것이다.
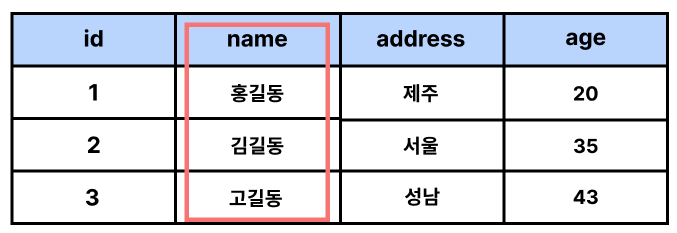
행 row/record/value
실제 데이터가 저장되는 형태이다.
위 테이블에서 행이란 3명의 고객 정보가 저장되어 있는 것이다.
즉, 저장된 데이터는 행 / 로우 / 레코드 / 값이라고 부르며,
이러한 데이터의 형식을 묶어주는 역할을 열 / 컬럼 / 필드라고 부른다.

기본키 PK;Primary Key
- 각 행의 고유값이다.
- 기본키는 절대로 중복이 발생되지 않아야 한다.
- 기본키는 반드시 설정되어야 하며, 데이터베이스 관리 및 관계 설정 시 주요하게 활용된다.
- 주민등록번호, 학번 등과 같은 개념이다.

RDBMS 관계형 데이터베이스 관리 시스템
- 관계형 모델을 기반으로 데이터베이스를 관시하는 시스템을 의미한다.
- ex. MySQL, oracle, SQLite 등
SQLite Data Type
- NULL
- INTEGER (INT)
- REAL
- 부동 소수점 값
- TEXT
- BLOB
- 입력된 그대로 저장된 데이터 (별다른 타입 없이 저장)
Typenames from the CREATE table statement and Resulting affinity
INTEGER
- INT, INTEGER, TUNYINT, SMALLINT, MEDIUMINT, BIGINT, UNSIGNED BIG INT, INT2, INT8
TEXT
- CHARACTER(20), VARCHAR(255), VARYING CHARACTER(255), NCHAR(55), NATIVE CHARACTER(70), NVARCHAR(100), TEXT, CLOB
BLOB
- no datatype
REAL
- REAL, DOUBLE, DOUBLE PRECISION, FLOAT
NUMERIC
- NUMERIC, DECIMAL(10, 5), BOOLEAN, DATE, DATETIME
SQL; Structured Query Language
- 데이터 관리를 위해 설계된 특수 목적으로 만들어진 프로그래밍 언어이다.
- 데이터베이스 스키마 생성 및 수정할 수 있다.
- 자료를 검색 및 관리할 수 있다.
- 데이터베이스의 객체 접근을 조정 및 관리한다.
DDL; Data Definition Language, 데이터 정의 언어
- 관계형 데이터베이스의 구조(테이블, 스키마)를 정의한다.
- CREATE, DROP, ALTER
- 테이블 및 스키마 생성, 삭제, 변경
DML; Data Manipulation Language, 데이터 조작 언어
- 데이터를 저장, 조회, 수정, 삭제 등을 명령한다.
- INSERT, SELECT, UPDATE, DELETE
DCL; Data Control Language, 데이터 제어 언어
- 데이터베이스 사용자의 권한을 제어하기 위해 사용한다
- GRANT, REVOKE, COMMIT, ROLLBACK
테이블 생성 및 삭제
CREATE
데이터베이스에서 테이블을 생성한다.
CREATE TABLE classmates (
id INTEGER PRIMARY KEY,
name TEXT
);sqlite> .table
classmates examples
sqlite> .schema classmates
CREATE TABLE classmates (
id INTEGER PRIMARY KEY,
name TEXT
);테이블 생성 후 테이블을 확인한다.
.table로 테이블 명을 조회한다.
.schema classmates 를 통해 특정 테이블의 스키마를 조회할 수 있다.
DROP
DROP TABLE classmates;
sqlite> .tables
exampleDROP 을 통해 테이블 자체를 삭제한다.
필드 제약 조건
- NOT NULL: NULL 값 입력 금지
- UNIQUE: 중복 값 입력 금지 (NULL 값은 중복 입력 가능)
- PRIMARY KEY: 테이블에서 반드시 하나로 존재한다. (NOT NULL + UNIQUE)
- FOREIGN KEY: 외래키, 다른 테이블의 PK이다.
- CHECK: 조건으로 설정된 값만 입력을 허용한다.
- DEFAULT: 기본값을 설정한다.
CRUD
CREATE, READ, UPDATE, DELETE
CREATE
INSERT
- "insert a single row into a table"
- 테이블에 단일 행을 삽입한다.
INSERT INTO NAME OF TABLE (COL1, COL2) VALUES (VAL1, VAL2);- 테이블에 정의된 모든 컬럼에 맞춰 순서대로 입력한다.
INSERT INTO NAME OF TABLE VALUES (VAL1, VAL2, VAL3)예문
classmates 테이블에 이름이 홍길동이고, 나이가 23인 데이터를 추가한다.
이후 이름 홍길동, 나이 30, 주소 서울인 데이터를 추가한다.
INSERT INTO classmates (name, age) VALUES ('홍길동', 23);
INSERT INTO classmates (name, age, address) VALUES ('홍길동', 30, '서울');sqlite> SELECT * FROM classmates;
name age address
--------- ---------- ---------
홍길동 23
홍길동 30 서울 첫 번째 홍길동의 주소가 빠진 데이터를 받게된다.
sqlite> SELECT rowid * FROM classmates;
rowid name age address
------ --------- ---------- ---------
1 홍길동 23
2 홍길동 30 서울rowid는 SQLite에서 자동으로 제공하고 있는 PK이다.
Primary Key가 없는 경우 자동으로 PK 컬럼이 증가한다.
sqlite> CREATE TABLE classmates (
id INT PRIMARY KEY,
name TEXT NOT NULL,
age INT NOT NULL,
address TEXT NOT NULL
);빠짐없이 데이터를 받기 위해 테이블 생성 시 'NOT NULL'을 설정해야 한다.
READ
SELECT
- "query data from a table"
- 테이블에서 데이터를 조회한다.
- 다양한 절과 함께 사용한다.
- ORDER BY, DISTINCT, WHERE, LIMIT, GROUP BY, etc.
SELECT (조회하고 싶은 컬럼명) FROM (테이블명)LIMIT
- "constrain the number of rows returned by a query"
- 쿼리로 반환하는 행의 수를 제한한다.
- 특정 행부터 시작해서 조회하기 위해 OFFSET 키워드와 함께 사용하기도 한다.
OFFSET
처음부터 주어진 요소나 지점까지의 차이를 나타내는 정수형으로 명령한다.
SELECT rowid, name FROM classmates LIMIT 2;
-- rowid name
-- ----- ----
-- 1 홍길동
-- 2 김철수
SELECT rowid, name FROM classmates LIMIT 1 OFFSET 2;
-- rowid name
-- ----- ----
-- 3 이호영즉, 2칸 띄우고 출력함을 의미한다. WHERE
- 특정 검색 조건을 지정한다.
SELECT * FROM classmates WHERE address='서울';
-- name age address
-- ---- --- -------
-- 홍길동 30 서울
SELECT name FROM classmates WHERE age >= 30;
-- name
-- ----
-- 홍길동
-- 김철수SELECT DISTINCT
- 조회 결과에서 중복 행을 제거한다.
SELECT DISTINCT age FROM classmates;
-- age
-- ---
-- 30
-- 26
-- 29
-- 28UPDATE
- 데이터를 수정한다.
- 특정한 조건이 필요하다. (rowid=#와 같은 조건을 where절과 함께 입력한다. )
UPDATE classmates SET name='홍길동', address='제주도' WHERE rowid=5;
SELECT rowid, * FROM classmates;
rowid name age address
----- ---- --- -------
1 홍길동 30 서울
2 김철수 30 제주
3 이호영 26 인천
4 박민희 29 대구
5 홍길동 40 제주도수정과 삭제는 primary key를 기준한다.
즉, rowid(id)를 기준으로 수정과 삭제가 이루어진다.
DELETE
- 데이터를 제거한다.
- 특정한 조건이 필요하다. (rowid=#와 같은 조건을 where절과 함께 입력한다. )
DELETE FROM classmates WHERE rowid=5;
rowid name age address
----- ---- --- -------
1 홍길동 30 서울
2 김철수 30 제주
3 이호영 26 인천
4 박민희 29 대구
'SQL' 카테고리의 다른 글
| [이론] 데이터베이스 모델링, ERD (0) | 2022.08.23 |
|---|---|
| [이론] JOIN (0) | 2022.08.22 |
| [이론] CASE, SubQuery (0) | 2022.08.19 |
| [이론] Aggregate Function 집계 함수, GROUP BY (0) | 2022.08.18 |
| [이론] WHERE Syntax (0) | 2022.08.17 |