gt 초과
greater than
날짜 연산도 가능하다.
Entry.objects.filter(id__gt=4)
# sql.ver
SELECT ... WHERE id > 4;(id__gt=4) 는 메서드 호출이다.
gte 이상
greater than equal
Entry.objects.filter(id__gte=4)
# sql.ver
SELECT ... WHERE id >= 4;lt 미만
Entry.objects.filter(id__lt=4)
# sql.ver
SELECT ... WHERE id < 4;lte 이하
Entry.objects.filter(id__lte=4)
# sql.ver
SELECT ... WHERE id <= 4;in
포함관계
Entry.objects.filter(id__in=[1, 3, 4])
Entry.objects.filter(headline__in='abc')
# sql.ver
SELECT ... WHERE id IN (1, 3, 4);
SELECT ... WHERE headline IN ('a', 'b', 'c');startswith
Entry.objects.filter(headline__startswith='Lennon')
# sql.ver
SELECT ... WHERE headline LIKE 'Lennon%';접미사, 접두사를 찾는다.
SQL의 와일드카드와 같은 역할을 한다.
시작이 Lennon인 값을 찾는다.
.filter()를 사용한다.
istartswith
Entry.objects.filter(headline__istartswith='Lennon')
# sql.ver
SELECT ... WHERE headline ILIKE 'Lennon%';istartswith는 대소문자 관계 없이 값을 찾는다.
마찬가지로 시작이 Lennon인 값을 찾는다.
endswith
Entry.objects.filter(headline__endswith='Lennon’)
Entry.objects.filter(headline__iendswith='Lennon')
# sql.ver
SELECT ... WHERE headline LIKE '%Lennon';
SELECT ... WHERE headline ILIKE '%Lennon'끝이 Lennon인 값을 찾는다.
contains
Entry.objects.get(headline__contains='Lennon’)
Entry.objects.get(headline__icontains='Lennon’)
# sql.ver
SELECT ... WHERE headline LIKE '%Lennon%’;
SELECT ... WHERE headline ILIKE '%Lennon%';.get()을 사용한다 .
Lennon이 속한 값을 찾는다.
찾고자하는 값 양쪽에 %를 추가한 SQL문과 같은 역할을 한다.
range
import datetime
start_date = datetime.date(2005, 1, 1)
end_date = datetime.date(2005, 3, 31)
Entry.objects.filter(pub_date__range=(start_date, end_date))
# sql.ver
SELECT ... WHERE pub_date
BETWEEN '2005-01-01' and '2005-03-31';range의 기능을 할 수 있다.
날짜를 찾는다고 가정하였을 때, start_date와 end_date를 설정한 후 \
.filter를 통해 range로 범위에 해당하는 값을 찾는다.
SQL은 BETWEEN의 역할과 같다.
서브쿼리
inner_qs = Blog.objects.filter(name__contains='Cheddar')
entries = Entry.objects.filter(blog__in=inner_qs)
# sql.ver
SELECT ...
WHERE blog.id IN (SELECT id FROM ... WHERE NAME LIKE '%Cheddar%’);위 구문의 두 문장은 inner_qs로 엮여져 있다.
SQL로 보면 IN을 통한 서브쿼리의 역할을 한다.
LIMIT
Entry.objects.all()[0]
# sql.ver
SELECT ...
LIMIT 1;.all()을 통해 인덱싱하는 것처럼 보이는 구문은 SQL에서는 LIMIT의 역할이다.
LIMIT & OFFSET
Entry.objects.all()[1:4]
# sql.ver
SELECT ...
LIMIT 3 OFFSET 1;만약 인덱스 슬라이싱을 한다면 SQL에서의 OFFSET의 역할과 같다.
ORDER BY
Entry.objects.order_by(‘id')
# sql.ver
SELECT ...
ORDER BY id;SQL의 ORDER BY는 .order_by( ) 로 표현한다.
ORDER BY DESC
Entry.objects.order_by(‘-id')
# sql.ver
SELECT ...
ORDER BY id DESC;내림차순은 '-'를 붙여준다.
ORM 확장 1: N
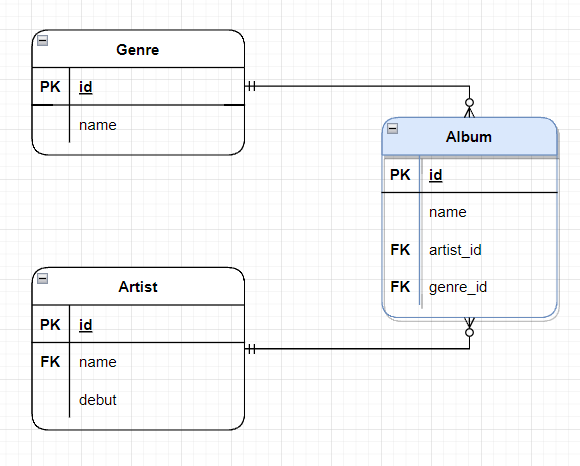
Genre, Artist, Album 테이블을 가지고 모델링을 한다고 가정해보자.
이때 Genre와 Artist는 1이고, Album은 N이다.
각각의 장르와 가수는 유일하지만,
하나의 장르 혹은 가수는 여러 개의 앨범을 가지고 있기 때문이다.
카디널리티 표현으로 쉽게 파악할 수 있다.
Genre와 Artist는 ||로 필수이자 하나를 가지고 있고,
Album은 O, <로 0개 혹은 그 이상을 가지고 있음을 나타내고 있다.
class Genre(models.Model):
name = models.CharField(max_length=30)
class Artist(models.Model):
name = models.CharField(max_length=30)
debut = models.DateField()
class Album(models.Model):
name = models.CharField(max_length=30)
genre = models.ForeignKey('Genre', on_delete=models.CASCADE)
artist = models.ForeignKey('Artist', on_delete=models.CASCADE)각 테이블을 클래스로, 컬럼을 속성으로 만들어준다.
이때 Album은 다수인 N의 성격을 가지고 있기 때문에 Foreign Key를 사용한다.
Foreign Key를 사용하는 이유는 클래스 간의 관계를 표현해주기 위함이다.
외래키 Foreign Key
- 부모 테이블의 유일한 값을 참조 (참조 무결성)
- 2개의 테이블 간의 일관성을 나타낸다.
- 외래키가 반드시 부모 테이블의 기본키일 필요 없다.
- 하지만, 유일한 값이어야 한다.
models.ForeignKey 필드
- 2개의 필수 위치 인자
- Model class
- on_delete
on_delete Action
CASCADE
- 부모 객체(참조 된 객체)가 삭제 됐을 때 이를 참조하는 객체도 삭제된다.
PROTECT
- 삭제되지 않도록 한다.
SET_NULL
- 부모 객체 삭제 시 자식 객체 필드가 NULL값으로 바뀐다.
SET_DEFAULT
- 부모 객체 삭제 시 자식 객체 필드가 기본값으로 바뀐다.
SOFT DELETE
RESTRICT
- 자식 객체에 PK값이 없는 경우만 부모 객체를 삭제하는 것을 허용한다.
NO ACTION
- 참조 무결성을 위반하는 삭제 및 수정 액션을 취하지 않는다.
이러한 옵션이 있는 이유는 참조 무결성이 중요하기 때문이다.
역참조: _set
만약 장르 id가 1인 앨범 이름을 출력하고자 한다면, 이는 역참조를 하는 것이다.
# 1. 참조
album = Album.objects.get(id=1)
album.artist
# <Artist: Artist object (1)>
album.genre
# <Genre: Genre object (1)>
# 2. 역참조
genre = Genre.objects.filter(id=1)
genre.album_set.all()
# <QuerySet [<Album: Album object (1)>, <Album:Album object (2)>]>
- 참조
Album에서 Album id가 1인 가수와 장르를 찾고자 할 때는 참조이다.
- 역참조
Album의 외래키로 참조하고 있는 Genre가 Genre id가 1인 Album을 찾고자 할 때는 역참조가 된다.
이때 역참조 시 _set을 사용해야 한다.
출력을 하게 되면 Album의 인스턴스가 담긴 QuerySet을 출력하게 된다.
왜냐하면 Genre과 Album의 관계는 1:N이기 때문이다.
Genre 입장에서 하나의 장르에 여러 개의 앨범을 가져오기 때문에 Album은 N이다.
print(Genre.objects.get(id=4))이 오류가 뜨는 이유는 인스턴스이기 때문이다.
'SQL' 카테고리의 다른 글
| QuerySet 실습 정리 (0) | 2022.08.25 |
|---|---|
| [이론] ORM, Object-Relational-Mapping (0) | 2022.08.24 |
| [이론] 데이터베이스 모델링, ERD (0) | 2022.08.23 |
| [이론] JOIN (0) | 2022.08.22 |
| [이론] CASE, SubQuery (0) | 2022.08.19 |