(이코테 w/ Python) 함수와 람다 표현식
함수란?
함수(function)란 특정한 작업을 하나의 단위로 묶어 놓은 것이다.
함수를 사용하면 불필요한 소스코드의 반복을 줄일 수 있다.
왜냐하면, 반복적인 작업을 함수로 묶어놓으면 추후에 호출하면 되기 때문에 소스코드의 양을 줄일 수 있다.
함수 종류
- 내장 함수: 파이썬이 기본으로 제공하는 함수이다
- 사용자 정의 함수: 직접 정의하여 사용하는 함수이다
함수 정의하기
- 매개변수: 함수 내부에서 사용할 변수이다
- 반환 값: 함수에서 처리 된 결과를 반환한다
def 함수명(매개변수):
실행할 소스코드
return 반환 값(def는 define의 약자로 함수를 정의하겠다는 의미이다.)

add라는 함수를 정의하였다.
3과 7의 인자값을 넣어주었기 때문에 10이라는 결과 값이 나올 수 있다.
(FYI, 함수를 호출할 때 넣는 값들은 (3, 7) argument (인자) 이다.
전달받고자 하는 값들을 명시해 놓은 변수(a, b)를 매개변수(parameter)라고 한다. )

return이 존재하지 않아도 된다.
함수 안에서 print 구문을 이용해도 된다.
Parameter(매개변수) 지정하기
파라미터의 변수를 직접 지정할 수 있다.
이 경우, 매개변수의 순서가 달라도 상관 없다.

직접 파라미터의 변수를 지정해서 넣을 수 있다.
global 키워드
global 키워드로 변수를 지정하면 해당 함수에서는 지역 변수를 만들지 않고, 함수 바깥에 선언된 변수를 바로 참조하게 된다.

a에 0 값을 넣고
fun() 함수를 10번 호출한다.
fun() 함수는 함수 바깥쪽에 있는 선언되어 있는 a를 참조해서 값을 1씩 증가한다.
a의 값을 1씩 증가시키는 과정을 10번 반복해서 a의 값은 10으로 출력되는 것이다.
global 키워드가 없다면,
fun() 내부에서 a 변수가 선언되지 않는 이상 a 변수를 인식하지 못한다.
전역변수로 리스트가 선언되어 있을 때는 global 키워드 없이 바깥쪽에 있는 리스트를 인식할 수 있다.
하지만, 전역변수와 지역변수 모두 존재할 때 전역변수와 지역변수가 동일한 이름의 변수가 존재한다면 함수 내부에서는 내부적으로 선언되어 있는 지역변수를 우선으로 한다.
여러 개의 반환 값

자동으로 여러 개의 값을 한꺼번에 return할 수 있다.
이를 패킹이라고 하고, 반환된 값들을 차례대로 특정 변수에 담는 것을 언패킹이라고 한다.
add, subtract, multiply, divide가 차례대로 a, b, c, d에 담기게 된다.
람다 표현식
람다 표현식을 이용하면 함수를 간단하게 작성할 수 있다.
특정한 기능을 수행하는 함수를 한 줄에 작성할 수 있다.

함수의 이름을 요구하지 않아 ‘이름 없는 함수'라고도 한다.
매개변수를 차례대로 명시해주고 콜론(:)을 넣어서 함수의 반환 값을 이어서 명시하면 된다.
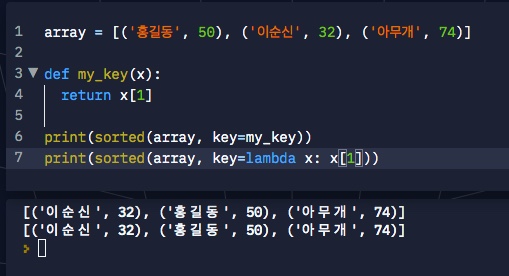
sorted나 sort 정렬 함수에서 람다 함수를 속성 값으로 간단하게 넣어줄 수 있다.
리스트의 모든 원소는 튜플 형태로 형성되어 있다.
학생의 점수들을 오름차순으로 정렬해보자.
이 경우 내장함수 중에서 sorted를 이용할 수 있다.
array 리스트로 정렬을 하되, 정렬 기준/key 속성으로는 어떠한 함수를 넣어주어서 정렬 기준을 명시할 수 있다.
x 원소가 있을 때, 즉 튜플이 주어졌을 때 2번째 원소를 기준으로 정렬을 수행하도록 명시하였다 (return x[1])
이러한 정렬 기준을 key 속성으로 넣어주어서 정렬을 수행하도록 한다.
정렬기준함수는 한 번만 사용되기 때문에 간단히 람다 함수로 사용하면 좋다.

여러 개의 리스트에 동일한 규칙을 갖는 하나의 함수를 적용하고자 할 때 람다 표현식을 효과적으로 사용할 수 있다.
map() 함수와 함께 사용되었다.
map() 함수는 각 원소에 함수를 적용하고자 할 때 사용한다.
예를 들어, 2개의 리스트가 있을 때 첫 번째 원소끼리, 두 번째 원소끼리, 세 번째 원소끼리, 순서에 맞는 원소 끼리 더한 결과를 별도의 리스트에 담을 수 있다.