오늘은 데이터 분석에서 기본적으로 이뤄져야하는 수집과 피벗테이블을 이용한 분석을 배웠다!
특히 엑셀에서 Power Pivot과 Power Query을 사용하여 데이터 수집부터 병합, 분석까지 실행하였다.
Pivot Table 피벗 테이블
피벗 테이블이란?
피벗테이블이란 많은 양의 데이터에서 필요한 자료만을 뽑아 새롭게 표를 작성해 주는 기능으로
임의대로 데이터를 정렬하고 필터링할 수 있다.
Pivot은 중심축이란 뜻으로 어떠한 관점을 중심으로 해당 관련 수치를 분석할 수 있도록 월별 매출, 제품별 매출, 이탈율 등을 측정할 수 있는 것이다.
데이터를 모델링 해주는 역할을 수행한다.
필드와 그룹핑
위 설명을 정리하자면 피벗테이블을 사용하여 탐색적 데이터 분석을 할 수 있다는 것이다. 이러한 맥락에서 대화형 테이블이라고도 설명할 수 있다.
피벗테이블의 핵심은 필드 설정과 그룹핑이다.
그러므로 각 필드의 데이터 타입이 중요하다.
주문 관련 데이터를 통해 전체 거래 건수가 얼마나 되는지 피벗테이블을 통해 찾아보자.
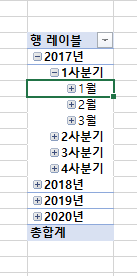
데이터 중에서 주문 일자를 행으로 놓았을 때 자동으로 계층구조를 만들고 연도별로 그룹핑을 하였다.
좌측의 필드에도 편리하게 사용할 수 있도록 년, 분기, 월, 일 필드가 생성된다.
이러한 자동 기능이 분석의 관점을 만들어 주는 것이다.
더 나아가서 각 고객의 첫 주문 날짜를 알아보자.
위에서 주문 일자를 행으로 설정하여 피벗테이블을 생성한 것 처럼 고객 번호를 행이나 열로 설정하면 각 고객의 주문 관련 데이터가 나올까?
그렇지 않다,, 원본 데이터에는 주문 기준의 고객과 배송 관련 모든 데이터가 담겨있는데 위에서 실행한 피벗테이블로 중복된 고객 번호를 모두 다 구별해주지 않기 때문이다. (고유한 고객 번호를 인식할 수 없음 혹은 중복된 고객 번호를 제거하지 못함)
이를 위해서 Power Pivot을 사용해야 한다.
Power Pivot은 기존의 피벗테이블을 강화한 기능이 추가된 툴이다.
고유한 고객 분석
현재 우리의 문제는 고객번호를 값으로 피벗테이블을 사용할 때 고유한 고객 번호를 식별할 수 없기 때문에 고객별 첫 주문 날짜를 알 수 없다.
즉, 우리는 '고유'한 데이터 분석 기능이 필요하다.
Power Pivot을 통해 이를 해결해보자.
고객별 첫 주문을 구하기 위해서는 minifs 함수가 필요하다.
minifs(주문날짜 범위, 고객번호 범위, 고유고객번호) : 범위 내 여러개의 조건을 만족하는 최소값을 반환하는 것
실제 함수를 적용해보면 아래 형식으로 수식이 작성된다.
=MINIFS([주문 일자], [고객번호], [@고객번호])
위 함수에서 [@고객번호]는 기준이 되는 고객 번호이다.
즉, 각 행에 존재하는 고객의 고유의 고객번호를 인식할 수 있다.
때문에 해당 행의 고객 번호에 따라 첫 주문 해 데이터가 반환될 수 있다.
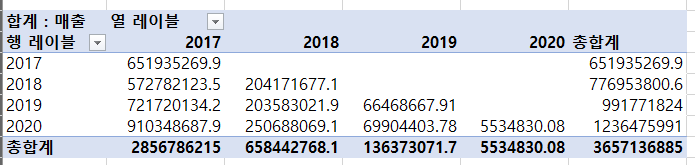
좌측상단의 필드를 확인해보면 '합계: 매출'로 나타나있다.
우리는 합계가 아닌 고객의 수를 알아봐야하므로 '고유 개수'를 선택해보자.
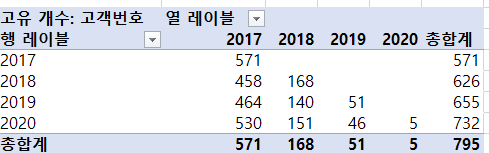
필드 설정에서 '고유 개수'를 선택하면 우리가 원하는 연도별, 고객 번호 별 첫 구매 연도를 알 수 있게 되었다.
다시 말해서 위 테이블은 행은 연도별로 정리한 것이고, 열은 고객 번호 별 첫 구매 연도를 구별해 놓은 것이다.
추가적으로, 열에서 2017년(첫 주문해)과 행에서 2018(연도)년의 데이터는 재구매한 고객의 수를 구한 것이다.
총 활동 고객은 795명이고 2017년의 첫주문 고객은 571명으로 알 수 있다.
요약: 고객 번호의 필드를 고유개수로 설정해줘야 한다.
데이터 수집
위 주문 데이터를 다양한 관점에서 데이터를 분석할 수 있도록 대시보드와 같은 시트를 만들어 보고서를 만들어 보자!
Power Query
파워 쿼리는 다양한 데이터를 추출해서 연결해주는 역할을 수행한다.
파워 쿼리를 통해 데이터를 추출하고 저장하는 것은 저장 공간에 많은 메모리를 소요하지 않아 큰 장점이 있다.
그 이유는 필요없는 열과 행을 제거하고 테이블들을 통합해준다.
위와 같은 이유로 파워 쿼리는 Mashup language, M language라고 한다.
Power Query 사용해보기
엑셀의 파워 쿼리의 아주 아주 큰 장점은 흩어져있는 데이터 파일들을 폴더 형식으로 업로드하여 깔끔하게 자동으로 병합할 수 있다는 것이다.
폴더를 추가하는 방식은 병합된 데이터나 테이블이 행으로 (아래로) 병합하는 방식이다.
파워 쿼리를 통해 폴더를 추가해주면 되는데, 이때 폴더의 경로는 링크 형식으로 가져오는 것이다.
(그러므로 폴더 경로 설정이 중요하다!)

각 파일의 데이터들을 잘 읽어서 결합할 수 있도록 준비해둔 것을 볼 수 있다.
결합 및 변환을 누르고, 파일 병합이 된 것을 확인해본다.
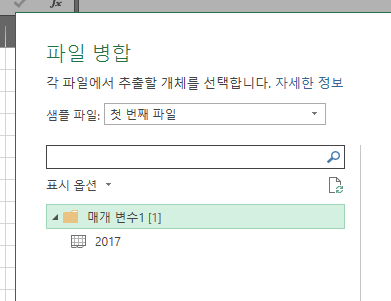
한번에 병합하기 위해서는 꼬옥 노란 아이콘인 폴더를 누른 뒤 (파일을 누르면 병합이 되지 않는다!)
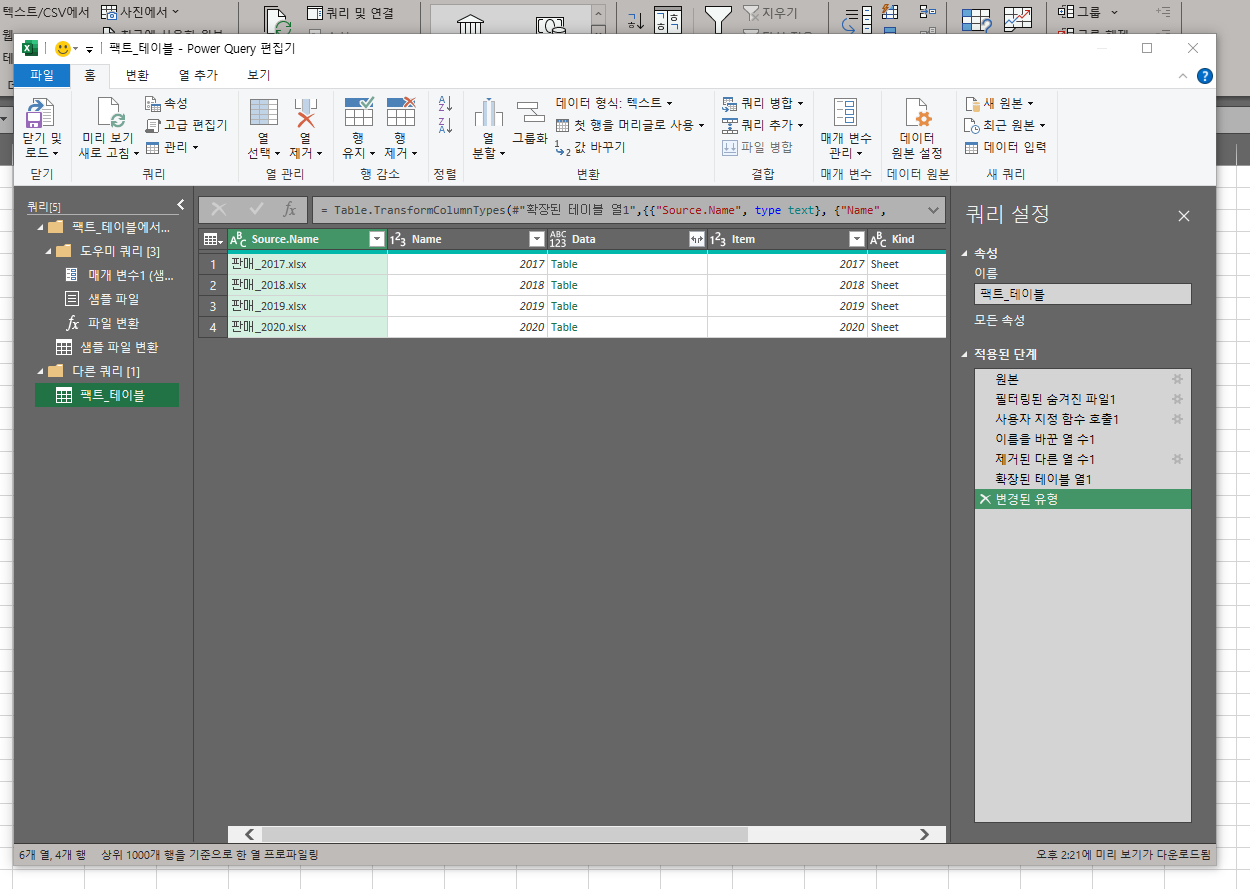
이후 새로운 파워 쿼리 창이 띄워진다.
테이블 형태로 변환해준 것이다.
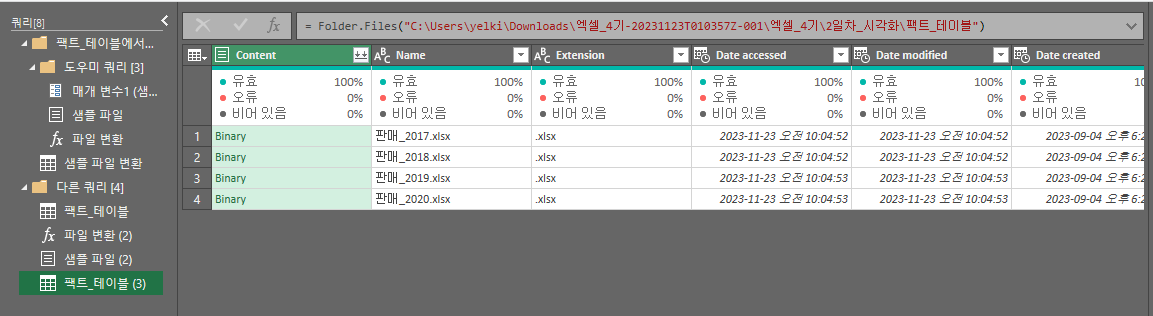
그냥 ‘데이터 변환’을 선택한다면 바이너리 형태로 파워 쿼리 창이 띄워질 것이다.
컨텐츠, 이름 등의 필드가 생긴 것을 확인할 수 있다.
위 테이블은 데이터의 업데이트가 활발하게 이루어지게 연출한 쿼리 테이블이다.
바이너리는 하나의 셀 안에 하나의 값이 아닌 파일을 담은 것이다.
추출하였지만 세부 데이터를 확인하지 않는 상태로 보면 된다.
Ctrl + Z를 실행할 수 없지만 저장 기록을 남겨준다.
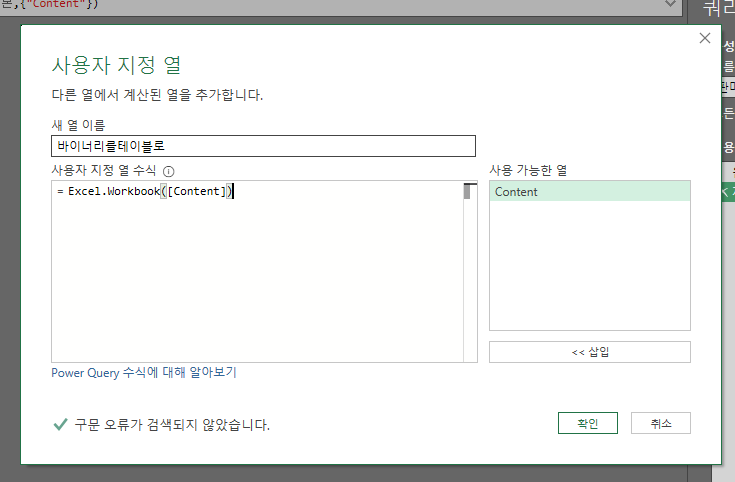
열 추가를 위한 함수(= Excel.Workbook([Content]))를 사용하기 위해 수식을 작성한다.
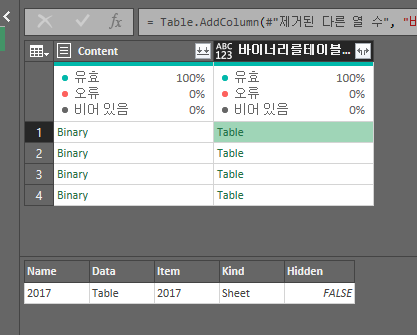
열을 추가하면 파일만 들어가 있는 형태이기 때문에 확장해주어 데이터를 펼쳐준다.
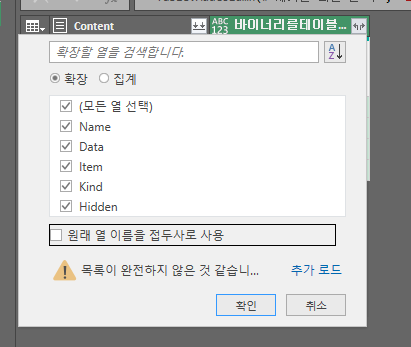
이후 열을 확장하여 자세한 데이터를 가져온다.
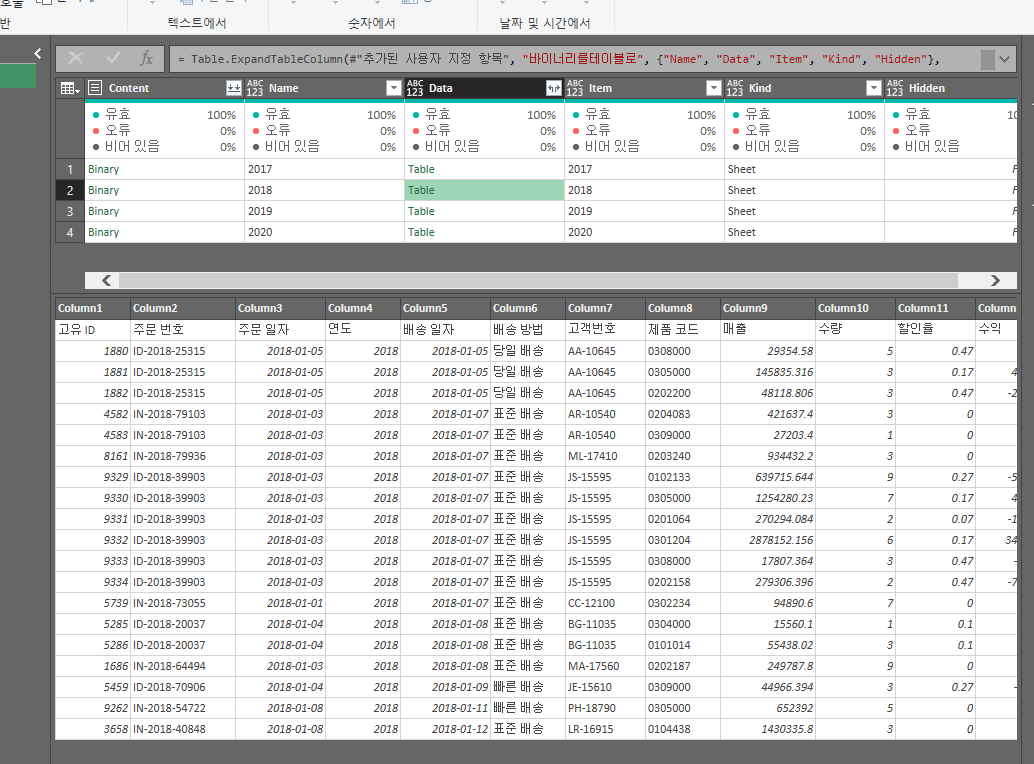
실행해준다면 이렇게 데이터가 담겨진다.
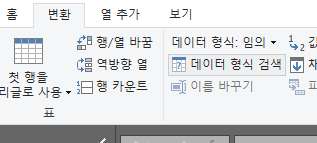
분석에 있어 중요한 것은 각 필드의 데이터 타입이 클리닝되었는지이다.
이를 위해서 위 이미지처럼 '변환' 탭에서 '데이터 형식 검색'을 눌러 자동으로 데이터 타입을 지정해주자.
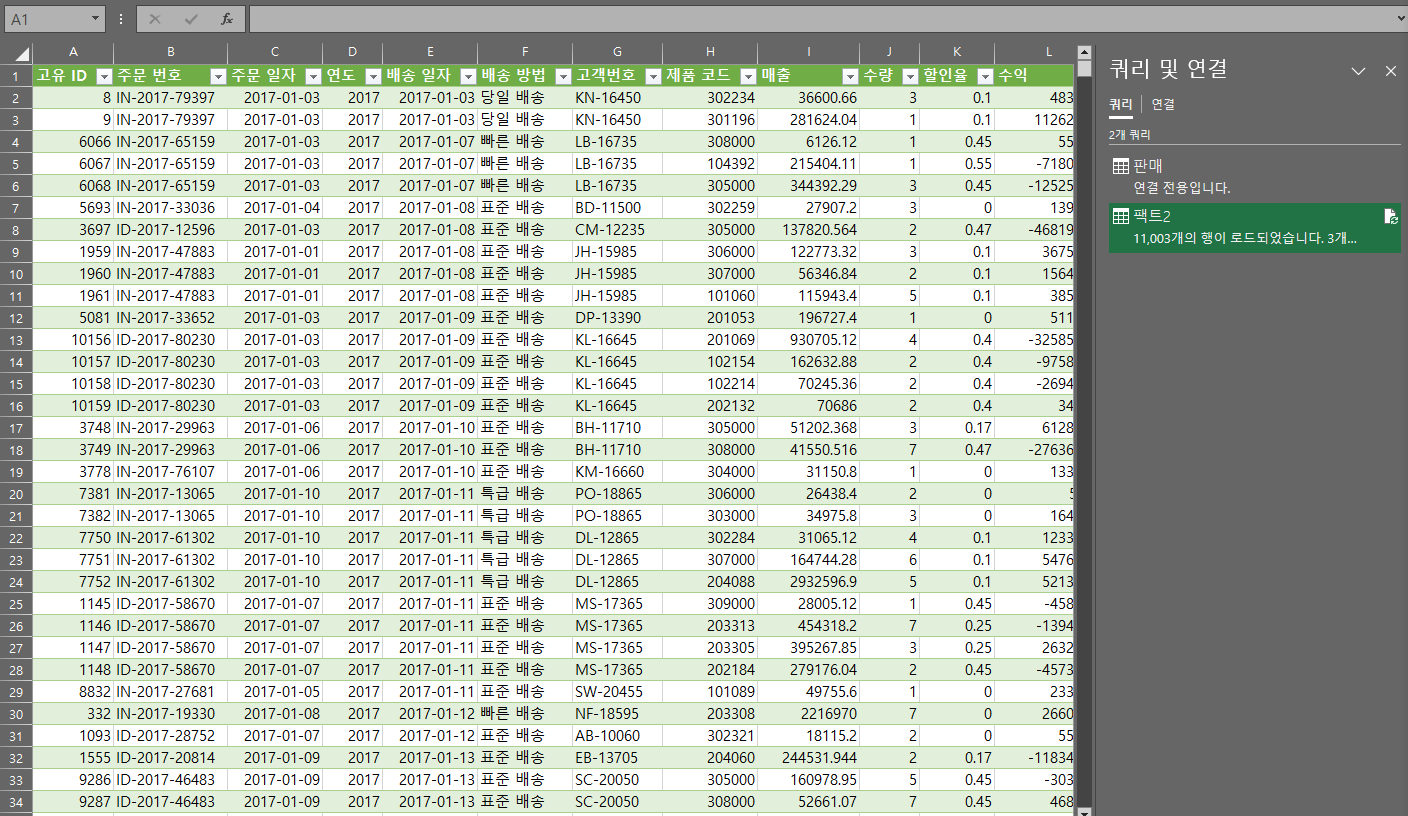
데이터 타입 클리닝 후 로드해서 엑셀로 넘어오면 이러한 모습이 된다!
주문 일자, 배송일자 시계열로 분석이 가능하고, 매출, 수량 데이터를 분석할 수 있다.
고객 관련 데이터 분석
위 데이터에서 고객의 이름, 배송지 등 고객 정보를 붙여보자.
두 가지의 방법이 있는데 한가지는 고객 번호를 기반으로 관계가 있음을 증명하여 데이터를 합친다. 이는 파워 피봇으로 진행할 수 있다.
두 번째는 병합하는 방법이다. 즉 열이 늘어나는 방법으로 이는 파워 쿼리로 진행할 수 있다.
Power Query를 통한 데이터 및 테이블 병합
두 번째 방법인 파워 쿼리로 진행해보자.
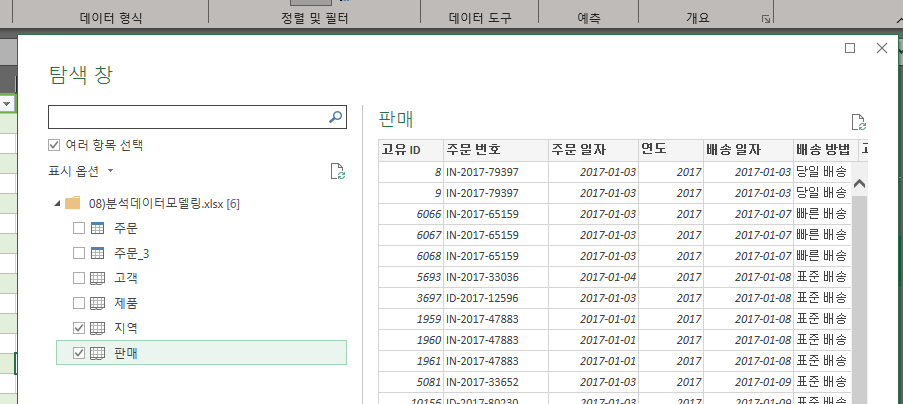
먼저, 고객의 고객 파일과 지역 파일로 가져오자.
이러한 작업은 파일을 병합해서 열의 개수를 늘리는 것이다.
위 이미지의 버튼을 통해 쿼리를 병합해보자~!
정말 정말 주의해야 할 사항은 병합 시 공통된 필드가 있어야 한다.
관계를 통해 테이블끼리 엮어준다고 생각하면 된다. SQL의 JOIN과 같은 개념이다.
SQL JOIN 개념
https://yelkim0210.tistory.com/81
[이론] JOIN
JOIN 관계형 데이터베이스의 큰 장점이자 핵심적인 기능이다. 일반적으로 데이터베이스에는 하나의 테이블에 많은 데이터를 저장하는 것이 아니라 여러 테이블로 나눠 저장한다. 그러므로 여러
yelkim0210.tistory.com
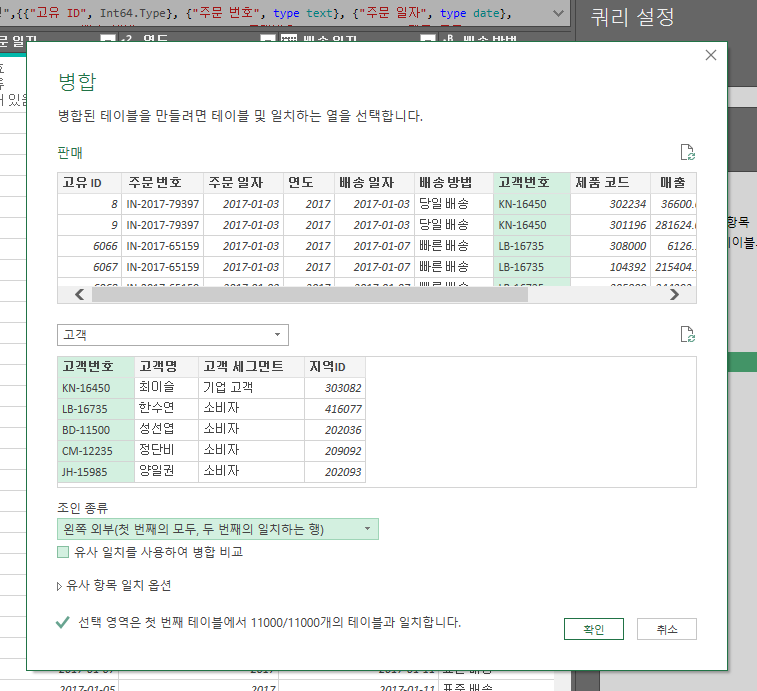
위 이미지처럼 공통된 필드를 선택해준다.
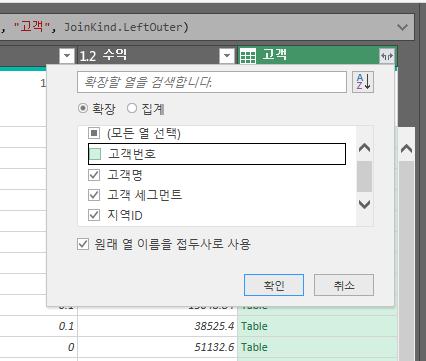
이후 한개의 열 형태인 고객 테이블로 병합이 된다.
고객번호는 이미 있으니 나머지 필드를 확장해준다.
이 과정은 엑셀에서 VLOOKUP을 일일히 작업을 해줘야 하는 과정과 똑같다.
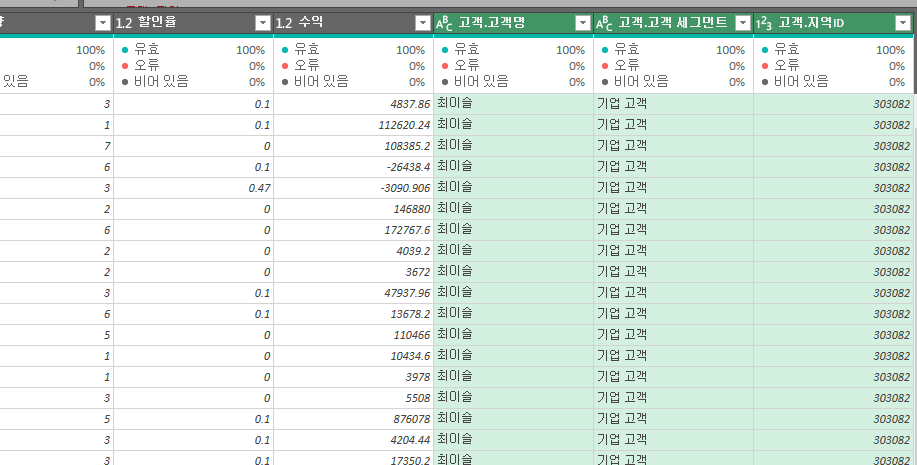
우측에 고객 관련 필드가 추가된 모습을 볼 수 있다!
이후 로드한 후 엑셀로 돌아가 피벗테이블을 통해 원하는 수치를 분석하면 된다!
그동안 SQL의 쿼리문을 통해서 관계형 데이터베이스를 만들고 데이터를 삽입해본 경험이 많았는데 이러한 작업을 코드 없이 엑셀로 모두 편리하게 할 수 있다는 점에서 놀랐다. 폴더를 올려서 파일을 자동으로 통합해준 뒤 피벗테이블로 예측율이나 특정 카테고리별 고객 데이터를 분석할 수 있다는 점에서 실무 프로젝트를 진행할 때 아주 아주 아주 유용하게 사용할 수 있을 것 같다!!!!!! 갓엑셀 만세~~~~
'UX 디자인' 카테고리의 다른 글
| [UX] 피그마 프로토타입 (0) | 2023.11.28 |
|---|---|
| [UX] 피그마의 이해 (0) | 2023.11.27 |
| 데이터 시각화를 위한 엑셀 (2) | 2023.11.22 |
| [UX] 프로젝트에 적용할 수 있는 세세한 방법론들 (1) | 2023.11.21 |
| [UX] UX/UI란? (0) | 2023.11.20 |